LAEO-Net revisiting people Looking At Each Other in videos
摘要
本文解决了在视频序列中检测人互相看着对方的问题。
我们提出了LAEO-Net,这是一种用于确定视频中LAEO的新型深层CNN,与之前工作不同的是LAEO-Net将时空轨迹作为输入,并以此解释整体轨迹。 它由三个分支组成,其中两个分支代表角色的头部,另一个分支代表其相对位置。
此外,我们引入了两个新的LAEO数据集:UCO-LAEO和AVA-LAEO。 实验全面评估证明了LAEO Net确定两个人互相注视的状态及其发生时的帧窗口的能力。 我们的模型在现有的TVHID-LAEO视频数据集上取得了最先进的结果,大大优于以前的方法。
最后,我们将LAEO-Net应用于社交网络分析,在该分析中,我们根据人们LAEO的频率和持续时间自动推断出两人之间的社会关系。
引言
眼神交流(相互注视)是两个人之间非语言交流的重要组成部分。 眼神接触的持续时间和频率取决于参与者关系的性质,如吸引或对立关系,并且能反映出参与者之间的力量关系。
我们提出了一种新的用于确定视频材料中LAEO的深度卷积神经网络(CNN),即LAEO-Net。 先前的研究通常只考虑单个帧,与之不同,我们的方法通过使用时空模型确定在某时间段内两个人物是否互相注视。
逐帧LAEO的问题在于,当人物眨眼或瞬间移动其头部时,则该帧将被视为非LAEO,这会严重影响一段时间内LAEO测量的准确性。 我们提出的模型考虑了多个帧上的头部轨迹,并根据其头部的姿势和相对位置确定了两个人物在一段时间内是否为LAEO。
贡献:
-
引入了一个由三个分支组成的时空LAEO模型,一个分支用于每个角色的跟踪头部,一个分支用于其相对位置,以及一个融合块。
-
第一篇以轨迹为输入并在整体轨迹中解释人物LAEO,而不是仅使用单个帧。
-
引入两个新的数据集:
- (i)UCO-LAEO,由129个(3-12秒)片段组成
- (ii)AVA-LAEO,使用LAEO注释扩展了现有的大规模AVA数据集,用作训练和验证集
-
模型在现有 TVHIDLAEO 数据集上达到了最先进的水平()。
-
通过使用LAEO得分,从电视资料中的人物互动中计算出一个社交网络。
LAEO-Net
给定一个视频片段,我们的目标是确定是否有两个人在看着对方(LAEO)。
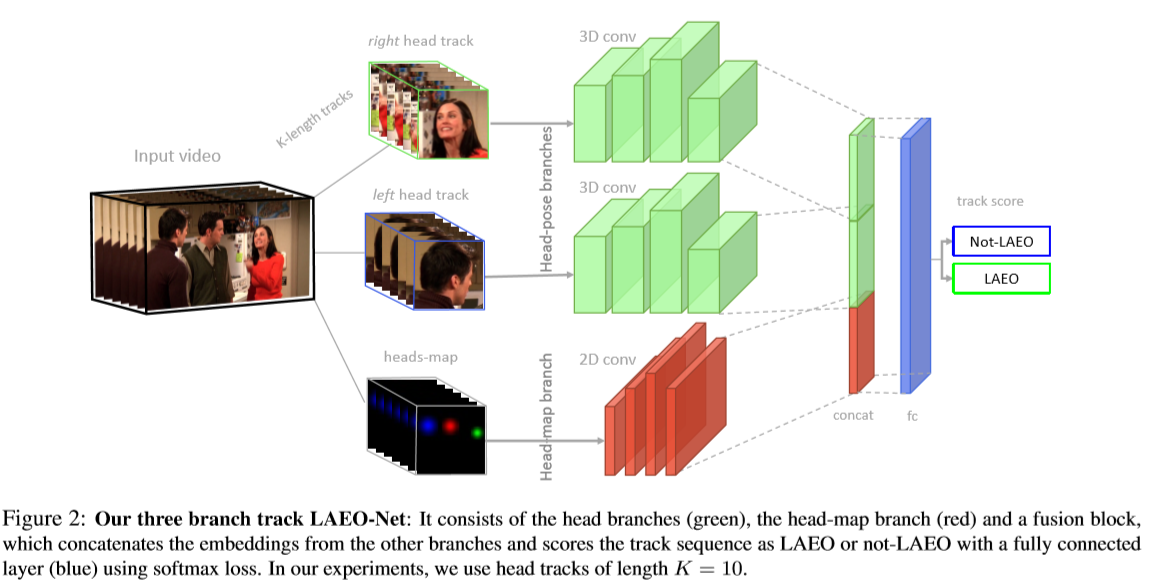
LAEO-Net由三个输入分支,一个融合层和一个全连接的层组成,如图2所示。其中两个输入流确定了头的姿势(绿色分支),第三个代表了它们的相对位置和比例 (红色分支)。 融合层将来自三个分支进行嵌入组合,再通过全连接层(蓝色层)预测LAEO分类。 该网络使用时空3D卷积,并可应用于视频剪辑中的头部轨道。
-
Head-pose 分支:
由两个人物分支构成组成,每个分支的输入是一个
64×64像素的K帧RGB裁剪张量,包含相同顺序的人物头部。每个分支对头部裁剪帧进行编码,其上有四个3D转换层,每层后跟一个dropout和一个flatten层(图2中的绿色分支)。 将flatten层的输出进行L2归一化,然后再用于进一步处理。 此分支将编码目标对的每个人的头部序列,从而获得两个嵌入向量。
每层的设置如下:

-
Head-map 分支:
该分支使用 Head-map 将两个头部轨迹之间的相对位置随时间嵌入。 特别的,我们定义一个
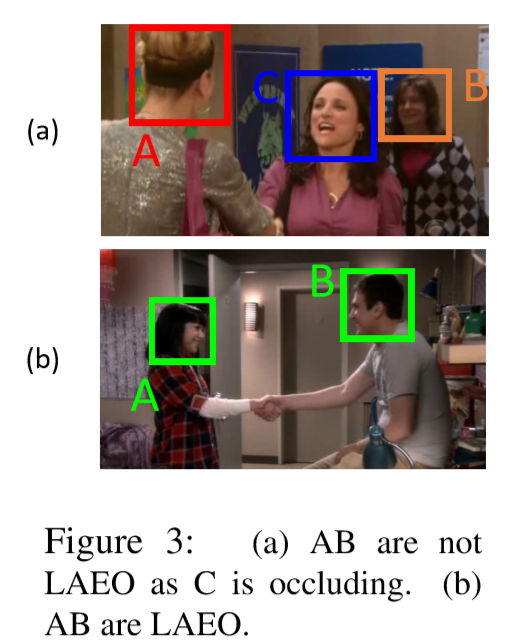
64 X 64的图来描述所有在K帧轨道中心检测到的头部的2D高斯图。除两个头部外,此分支还为场景中的其他人编码信息。 根据其大小和规模,第三个人可以在两个人物之间切割视线(图3), 此信息有助于LAEO-Net区分此类情况。
该分支由四个2D转换层组成(表1)。 为了获得head-map的嵌入,我们对最后一个conv层的输出进行整理,并应用L2归一化。
-
融合模块:
将不同分支的输出嵌入矢量连接起来,并由一个全连接层和一个交替的loss层(图2中的蓝色层)进行进一步处理。 最后接由两个隐藏单元(即表示非LAEO和LAEO类)组成的Softmax层。
-
LAEO loss 函数:
我们使用标准的二分类交叉熵作为损失:
其中, 是ground-truth类(0 表示不是 LAEO,1 表示是LAEO), 是对于类别 的预测可能性。
数据集
引入两个新的数据集:UCO-LAEO和AVA-LAEO,可用于训练和测试。
还引入了另外两个数据集:
- AFLW: 用于预训练 head-pose 分支并生成合成数据
- TVHID: 仅用于测试。 新引入的UCO-LAEO和AVALAEO数据集可用于培训和测试LAEO-Net。
带有注释的新数据集和评估代码可从以下网站在线获得:http//www.robots.ox.ac.uk/~vgg/research/laeonet/
UCO-LAEO 数据集
由129张(3-12秒长)的片段组成,每个帧中的所有头部都被框选出来,并被标注为LAEO或非LAEO。
标注设置:标注所有帧,确定此帧是否包含任何人物对的LAEO。视觉上模棱两可的案例被排除。 我们将100个LAEO片段分为77个训练数据,8个验证数据和15个测试数据。
AVA-LAEO 数据集
来自“Atomic Visual Actions”数据集(AVA v2.2),AVA帧使用每秒80个原子动作的边界框进行标注(每秒),且不包含LAEO标注; 因此,我们增强了有LAEO标注的子集中bounding-box的标签。
标注设置:
在训练集和验证集中,我们选择带有多个人的帧,并标注为“watch(一个人)”,分别得到40,166和10,631帧。 仅考虑观察者和被观察者都可见的情况(因为被观察者在框架中可能不可见)。
为了进行标注,我们遵循与UCO-LAEO中相同的过程,即在帧级别为LAEO(非LAEO)或模棱两可的情况下为每对人类边界框进行注释。
附加数据集
AFLW数据集。 使用“‘Annotated Facial Landmarks in the Wild”数据集来
(a)训练head-pose分支
(b)生成用于训练的合成数据
图像中,它包含约25,000个从FlickR获得的带标注的面孔,每个面孔都带有一组面部标志。 根据这些标志,可以估算出头部姿势(即偏航角,俯仰角和侧倾角)。 要创建一系列的头部剪裁,我们将输入图像复制K次。 将两个中间副本保持不变,并随机地扰动其他副本,即较小的偏移,缩放和亮度变化。
训练 LAEO-Net
头部检测及追踪
-
头部检测
头部检测检测整个头部,包括脸部(如果可见)以及后脑勺。 使用 Single Shot Multi-box Detector(SSD)来训练头部检测器。 以 (前50个epochs)的学习率训练模型,在其余的训练中将其降低0.1倍。 为了提高速度和获得更好的性能,我们使用批处理归一化,并使用数据增强来提高鲁棒性。
使用“Hollywood heads”数据集训练头像检测器。 它由1120帧的头部标注组成,分为720个训练帧和200个验证和测试帧。 我们首先使用训练集训练检测器,并在验证模型后,在整个数据集上进行训练,以作为提炼阶段。
-
头部追踪
获得头部检测器后,我们将其沿时间分组到轨迹中。对于构造轨道,我们使用在线链接算法,在所有的头部检测中,我们每帧只保留 个最高得分的对象。 如果检测的某帧得分最高,没有被其他轨道拾取且 (ov 表示重叠的部分),则将轨道 从帧 扩展到帧 。如果在M个连续的帧中不存在这样的帧,则轨道停止;否则,对头部检测进行插值。 轨道的分数定义为其检测的平均分数。 在给定的帧中,新的轨道从未拾取的头部检测开始。 为了避免轨道上的偏移效果,我们会同时向前和向后跟踪时间。
预训练和 head-pose 分支
由于图像分辨率或自遮挡的原因,我们仅根据头部的姿势对注视行为进行建模。
我们使用三个角度(按信息递减的顺序)对头部方向进行建模:
-
(a)偏航角,即向右,向左看
-
(b)俯仰角,即向上,向下看
-
(c)横滚角,即平面内旋转
我们使用这样的模型来预训练 head-pose 分支。从预训练中学到的权重,无需进一步调整(冻结权重)。
head-pose 预训练的损失函数。 令 分别表示偏航,俯仰和滚转角。 定义一个用于估计每个姿势角度的损失: 并用 损失进行建模。
鉴于偏航角是主要因素,我们制定了一条规则对偏航角符号的错误估计进行惩罚(如,无法确定人物是向左看还是向右看):
其中 是符号函数(即,对于正输入返回+1,对于负输入返回-1,如果输入为0则返回0)应用于偏航角, 是 ground truth。
因此,用于训练head-pose分支的损失函数 由下式给出:
其中 是在训练过程中通过交叉验证选择的正权重。由于 是决定头部方向的主要因素,我们在实验中使用:。 请注意,权重相加不必等于1。
训练 LAEO-Net
我们使用真实和合成数据训练LAEO-Net,同时使用数据增强技术,例如图像扰动,平移,亮度变化,缩放变化等。对于第一个 的epochs,我们仅使用合成数据训练LAEO-Net,然后在接下来的每一步训练中,交替使用真实数据和合成数据。 为了提高模型的性能,我们还使用了 hard negative mining。我们采用了课程学习策略,该策略通过在训练期调节 hard negatives incorporated 的难度来促进学习。 在我们的实验中,超参数 的值在 2 个 epoch 后增加,随着其值的增加,允许使用难度更大的例子。
合成数据。 为了生成其他合成数据,我们使用带有 head-pose 信息的图像。
-
为了生成正样本,我们选择角度与LAEO相符的头部图像对,同时生成一致的几何信息。
-
为了生成负样本,我们
-
(i)改变候选对的几何形状,破坏LAEO状态。例如,通过镜像使一个人的头部方向翻转
-
(ii)选择姿势与LAEO不相符的头部图像对,例如两者朝着同一方向看。
-

实验结果
实施细节。LAEO-Net 使用 Keras 实现。 为了训练LAEO-Net,我们使用 Adam 优化器对9个样本进行了mini-batches:4个正例,4个反例和1个不明例。 学习率初始为 ,当验证集上的 AP 连续 5 次迭代未提高时,学习率降低 倍,最小可调整至 。 Dropput 设置为 。 在将训练好的模型应用于测试集之前,使用最新的学习率,将 UCO-LAE 验证集的样本添加到训练集中,作为几个额外的epoch。
评估协议和评分方法
LAEO分类AP是我们用来评估LAEO预测的指标。
-
类似于物体检测,如果其与地面真实框重叠的交点 ,则检测是正确的。
-
如果两个head-map都正确定位并且其标签(LAEO,非LAEO)正确,则检测到的人物对是正确的。
-
性能用平均精度(AP)衡量,用Precision Recall(PR)曲线下的面积计算。如果标注不可用,则根据有效的 ground truth 标注,在帧级别(将每个人物对对视为独立样本),或镜头级别测量 AP。
合成数据的重要性
使用合成数据可以获得更多训练样本,从而使模型具有更高的可泛化性,同时减少了过度拟合的可能性。
在 UCO-LAEO 上训练和测试 LAEO-Net 得到 ,若在以下设置下进行训练:
-
(i)没有合成数据且没有 hard negative mining 的结果 ,即降低,
-
(ii)有合成数据但没有 hard negative mining 的结果 ,即降低 ,
-
(iii)没有合成数据但具有 hard negative mining 的结果 ,即降低 ,
-
(iv)仅使用合成数据(无真实数据和 hard negative mining)的结果 ,即减少 ,
这些结果表明在训练过程中使用合成数据的意义。
Ablation study
研究体系结构选择的影响,特别是head-map分支和时间窗口 的长度。
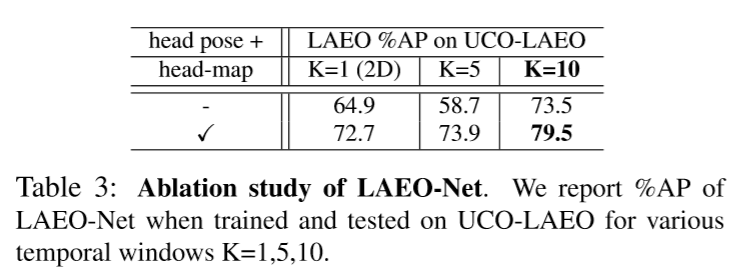
我们评估不带 head-map 分支的 LAEO-Net,观察到添加 head-map 分支可以改善性能(对于 ,从 提高到),它可以学习两个头部之间的空间关系。 此外,要评估使用 K 帧与使用单个帧相比时空窗口的重要性,用不同的 K 训练和评估LAEO-Net,其中 。表3显示,当K从仅 1 帧增加到 5 帧时,AP 性能有改善(1.2%),而当 K 从 1 到 10 帧增加时,AP 性能有显着提高()。 在这项工作中,我们使用 K = 10 帧。 训练 LAEO-Net 并冻结 head-map 分支的权重会使 提高至 ,这表明冻结权重会导致性能改进。
与替代架构的比较。 LAEO-Net 的核心分支是 head-pose 分支。 另外,我们使用 head-map 分支来描述轨迹中两个头部轨迹之间随时间的相对位置。 在这里,我们考虑了 head-map 的一种替代方法,即几何信息分支,其中,根据时间的变化,两个头部的相对位置是根据其几何形状进行编码的。
几何信息分支随时间推移嵌入了两个头部轨迹之间的相对位置(相对于 标准化参考系统),以及头部轨道的相对比例。 该分支输入是一个元组 ,其中 和 是从左头部 L 到 右头部 R 的向量的 和 分量,而 是两者之间的比例。 编码网络由两个全连接层组成,分别具有64个和16个隐藏单元。 因此,它输出一个16维向量来编码两个目标头部之间的几何关系。
当我们用几何分支替换 head-map 分支时,对于 UCO-LAEO 和 ,具有几何分支的 LAEO-Net 的分类 AP 比具有 head-map 的 AP 小 。这与预期相同,即使两个分支都编码相同的信息(即两个头部的相对位置),head-map 分支也提供了更丰富的场景表示,因此结果是更好的 AP。请注意,同时使用 head-map 和几何分支不会导致任何进一步的性能改进,这实际上是两个分支的组合只是增加了网络参数的数量,而没有提供任何其他信息。 因此,我们得出结论,就 AP 性能而言,建议的 LAEO-Net 是最有效的体系结构。
UCO-LAEO和AVA-LAEO的结果
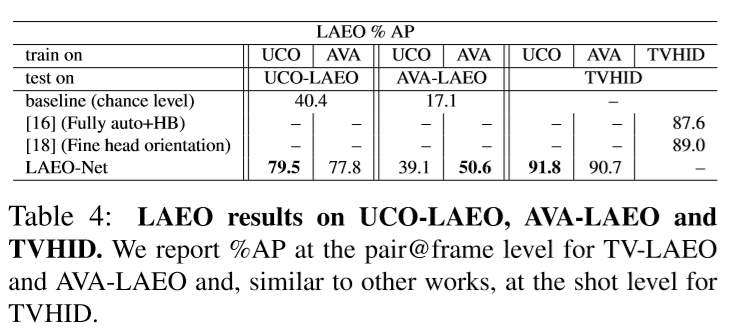
我们验证了模型 UCO-LAEO 和 AVA-LAEO 数据集上的结果,如表4所示。
-
在 UCO-LAEO 上进行训练和测试时,性能为 ,证明了我们模型的有效性。
-
在 AVA-LAEO 上进行训练和测试时,性能为 。
结果表明,UCO-LAEO 和 AVA-LAEO 之间的性能存在显着差距。 这是由于与其他数据集相比,AVA-LAEO的性质不同:
-
(1)未提供头部标注(仅每秒钟人的边界框)
-
(2)包含具有挑战性的视觉概念,例如(a)低分辨率电影,(b)场景中的许多人,(c)模糊,小脑袋和(d)特定的服装风格,尽管存在这些困难,但是 LAEO-Net 在 AVA-LAEO 上仍达到 。
为了检查 LAEO-Net 对其他数据集的一般性,我们还报告了在使用不同数据集进行训练和测试时的结果,如在 UCO-LAEO 为 ,在 AVA-LAEO 为 。这些结果表明,域移位确实会影响性能,但是同时我们的模型能够推广到其他未见数据集。 为了评估这些数据集的难度和 LAEO-Net 的有效性,我们还将其与 chance level 分类进行了比较,LAEO-Net 大大超过了 chance level:UCO-LAEO 为 ,AVA-LAEO 为 。
将 LAEO-Net 应用于 UCO-LAEO 和 AVA-LAEO时,我们得到图6的结果。对于这两个数据集,展示一些排名最高的LAEO人物对。

我们观察到,LAEO-Net 利用头部的方向及其时间一致性,准确地确定 LAEO 所在的帧。
TVHID-LAEO 的结果
我们将 LAEO-Net 与 TVHID 上的最新技术进行了比较,即唯一带有 LAEO 标注的视频数据集。 我们使用平均 AP 衡量 TVHID 的两个测试集。 在此数据集上,在 UCO-LAEO 和 AVA-LAEO 上训练的 LAEO-Net 分别实现 和 。 这两个结果都大大优于所有其他方法()。
我们将 LAEO-Net 应用到 TVHID 上,并获得图7所示的结果。

我们的模型在多种情况和场景下成功检测到人LAEO,例如不同的光照,比例,背景杂乱。 通过检查剩余的 错误,我们注意到在大多数错误下,ground truth 标签是不明确的 (图7中的前两个红色框)。 但是在某些情况下,头部姿势和相对位置不足以模拟 LAEO 情况,因为 LAEO 事件只能通过检查眼睛注视来确定(图7中最后一个红色框)。 我们的方法很难解决这类困难的情况,这些情况通常是通过眼动追踪技术来处理的。可能的扩展可能包括眼动追踪分支。
社交网络分析:朋友关系
一种确定社交意愿的基本方式是人们是否愿意 LAEO。眼神交流持续的时间和频率反映人与人之间的力量关系,吸引力或对抗性。 我们提出 LAEO-Net 在社交场景中的应用:给定头部轨迹,我们会根据人们 LAEO 随时间变化的频率和持续时间自动推断人与人之间的关系(例如彼此喜欢,浪漫的关系)。 特别的,计算人物 LAEO 的帧数与他们在同一场景的帧之间的比率能够确定其是否为朋友关系。 比率越高,它们之间的交互就越多。
数据集和过程。 在本实验中,我们使用电视节目“老友记”的两集(s03ep12和s05ep14)。 首先,检测并跟踪所有头部轨迹,这将导致近 3k 的头部轨迹。 然后,无需进一步训练,在每个轨道对上应用 LAEO-Net 来确定两个人物是否 LAEO。
人物标注。 为了确定头部轨迹对应于哪个人物,我们标注所有产生的头部轨迹,以描绘一个主要人物(超过一半的轨道),不相关的人物(约30%),错误的人物(约15%)或一些次要的人物(其余人物)。
实验与讨论。 我们的目标是自动了解角色之间的潜在关系。 因此,我们将两个人物之间的“相似度”作为两个人物并存的帧上的平均 LAEO 得分,并描绘出图8(更粗的边缘表示更高的分数和更强的关系)。
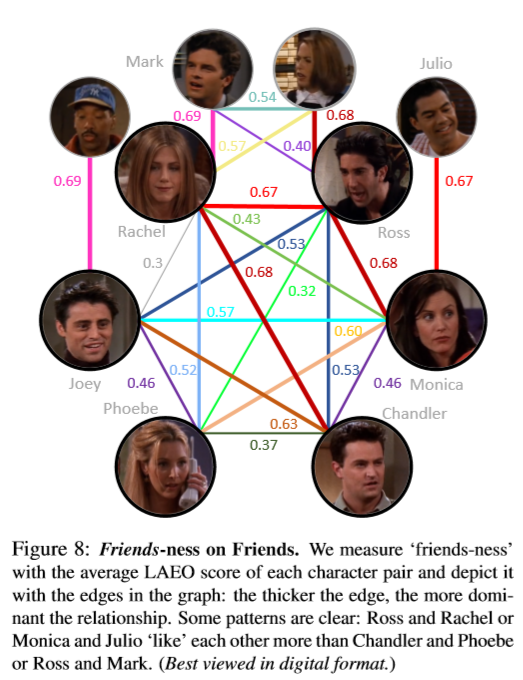
我们观察到 LAEO 得分捕获了角色之间的主要关系,例如罗斯和瑞秋与距离较远的角色,例如菲比和钱德勒。 我们的研究揭示了所有显着的配对关系,表明人们越是 LAEO,他们的互动和社会关系就越强。
结论
在本文中,我们着重介绍了视频中人们彼此注视(LAEO)的问题。 我们提出了 LAEO-Net,这是一种深度跟踪体系结构,该体系结构将头部轨道作为输入并确定轨道中的人是否为 LAEO。 这是首次使用轨道而不是边界框作为输入来推理整个轨道上的人的工作。LAEO-Net 由三个分支组成,一个分支用于跟踪每个角色的头部,另一个分支用于两个头部的相对位置。 此外,我们引入了两个新的 LAEO 视频数据集:UCO-LAEO 和 AVA-LAEO。我们的实验结果表明,LAEO-Net 能够正确检测 LAEO 事件及其发生的时间窗口。我们的模型在 TVHID-LAEO 数据集上实现了最新的结果。 最后,我们通过将模型应用于社会案例场景来证明我们模型的一般性,在该案例中,我们根据两个人的 LAEO 频率自动推断他们之间的社会关系。



